이 내용은 유튜버 Augmented Startups와 Mark Jay을 공부한 내용을 정리한 글입니다.
Augmented Startups: https://www.youtube.com/watch?v=GSDbfGsxruA&t=561s
Mark Jay: https://www.youtube.com/watch?v=lLM8oAsi32g
1. Mask RCNN-tensorflow버전 설치
Mask-RCNN-Tensorflow을 git clone 해준다
1 | $ git clone https://github.com/matterport/Mask_RCNN.git |
Dependencies을 설치해주자
먼저 필요한 python package들은 설치한다.
1 | $ cd Mask_RCNN |
그리고 pretrained model을 다운받고 Mask-RCNN 폴더에 옮겨주자
https://github.com/matterport/Mask_RCNN/releases/download/v2.0/mask_rcnn_coco.h5
이제 cocoapi를 설치하자
1 | $ git clone https://github.com/philferriere/cocoapi.git |
설치가 잘되었는지를 확인하기
터미널 창에 jupyter-notebook 입력해 쥬피터 노트북을 실행하고
samples 폴더안에 demo.jpynb를 실행시켜본다.
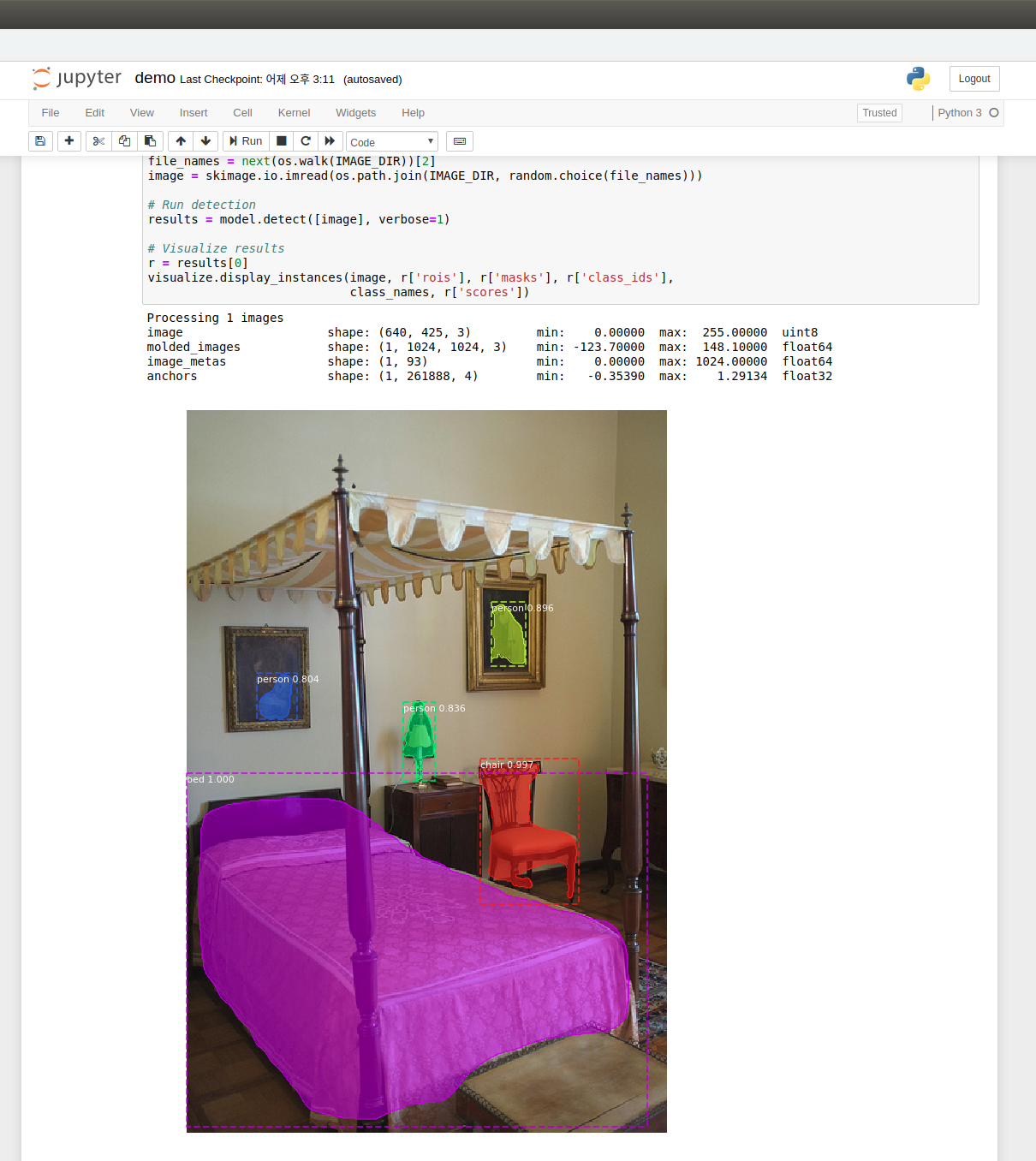
잘 설치된 경우 아래 그림과 같이 랜덤한 사진의 결과가 나온다.
Failed to get convolution algorithm 문제 발생시:
1 | import tensorflow as tf |
와 같이 텐서플로우를 import하고 sess를 적절한위치에 추가해주자
2. webcam과 video으로 테스트 해보기
webcam과 video 코드는 Mark Jay가 만든 코드를 사용할 것이다.
https://github.com/markjay4k/Mask-RCNN-series 에서
visualize_cv2.py
process_video.py
이 두개의 파일을 다운받는다.
그리고 visualize_cv2.py을 열어 다음과 같이 수정해준다.
1 | import utils -> from mrcnn import utils |
Failed to get convolution algorithm 문제 발생하면 위에 해결법을 이용하면 된다.
비디오 테스트에 경우 process_video.py에서
capture = cv2.VideoCapture('비디오 주소') 만 자신의 비디오 주소로 변경하면 된다.
3. 간단한 코드 분석
1 | import cv2 |
여기서 이용할 수 있는 부분은 results에서 나온 roi, masks, class_id로 어떤물체의 위치와 크기 이다.
Mask-RCNN Train
먼저 https://supervise.ly/이 사이트에 가입하고 사이트에 로그인한다.
.png)
그 후
- Import 탭에 들어간 후
- Import Plugin을 Images로 바꾸고 자신의 데이터셋 폴더를 위 그림의 상자안에 드래그 드랍 합니다.
.png)
그러면 위 사진처럼 창이 바뀌면
- 칸에 Project이름을 작성한후
- Start Import 버튼을 누르면 Import가 됩니다.
.png)
- Project 탭에 들어가면 그림과 같이 자신이 Import한 이미지의 Project가 생성된 것을 확인할 수 있습니다.
.png)
이제 프로젝트를 클릭하고 이미지 폴더에 들어가면 다음과 같은 창이 열린다. 여기서 빨간색 박스가 쳐진 버튼을 클릭합니다.
.png)
그러면 이런 창이 뜨는데 여기서 Title에 물체의 label을 지정합니다.
.png)
그 후 그림처럼 labeling을 진행 합니다.
.png)
그리고 class를 하나더 추가하고 싶으면 위 그림처럼 Create Class를 눌러 추가 해주면됩니다.
.png)
labeling을 다 했으면 다시 프로젝트 탭으로 돌아온후 위 그림처럼 Instance segmentation 버튼을 클릭해준다.
.png)
- Cluster 탭에 들어간 후
- Instructions을 클릭합니다.
.png)
그러면 위 같은 창이 뜨는데 먼저
- nvidia docker를 설치합니다.
.png)
- Neural Networks 탭에 들어간 후
- ADD 버튼을 클릭합니다.
.png)
그 후 아래로 내려보면 Mask-RCNN이 있고 ADD버튼을 눌러준다.
.png)
Neural Networks 탭에 다시 들어간 후 Train 버튼을 누른다.
.png)
- 자신의 데이터셋을 input project에 입력해주고
- 결과의 project이름을 정해준다.
.png)
Train이 끝나면 다음과 같이 새로운 Neural Network가 생기고 여기서 Download를 해주거나 test버튼을 눌러 test 데이터를 test할 수 있다.
만약 Download한다면 .tar파일 안에 model.h5라는 파일 있는데 이 파일을 Mask-RCNN 폴더에 옮겨준다.
.png)
그리고 위 코드처럼 바꿔준다. 여기서 NUM_CLASSES 에서 뒤에 있는 2는 자신이 train 시킨 클래스의 수를 적어준다.
https://deepmi.me/linux/18791/
- nvidia docker를 설치 했으면 그림에 있는 명령어를 터미널에 입력합니다.
TODO
Mask-RCNN을 자신만의 데이터로 training 하기